
Vem stämmer vem i AI: kartan över de 100 stämningarna som förklarar allt
För att ChatGPT, Gemini eller Meta AI ska kunna svara bra på det enorma antal frågor som deras användare ställer varje dag, år innan företagen bakom dem fattade ett beslut: att skaffa data till varje pris och var som helst. Böcker, tidningsartiklar, sångtexter, illustrationer, källkod. Hans utgångspunkt var tydlig: det var bättre att be om förlåtelse än att be om lov.
Så idag är domstolarna fulla av stämningar, miljarder dollar på spel och AI-affärsmodellen i hamnen. I åratal var piratkopiering en fråga om att individer laddade ner filmer. Nu är det de största företagen i världen som gjort något liknande, men i stor skala och med teknik som strukturellt bryter mot det.
Vad domarna bestämmer kommer att markera hur artificiell intelligens byggs upp från och med nu. Precis som man förbereder sig bättre inför en tentamen om man förutom att ta klassboken går till biblioteket och läser rekommenderade böcker och utökar med andra läsningar kopplade till ämnet man granskar, tyckte de olika forskarteamen bakom de stora AI-modellerna att med enorma datamängder och från olika källor blev resultatet bättre. Problemet är att denna enorma mängd data inte faller från himlen: de tog den från webben, från digitala bibliotek och från LibGen- eller Z-Library-förråd.
Det vanliga försvaret av företag som OpenAI är tillåten användning och undantag för text- och datautvinning, vilket säkerställer att de använder olicensierad data på ett legitimt sätt. Så domstolarna går från fall till fall. I Xataka En advokatbyrå IA har precis vunnit sin första rättegång.
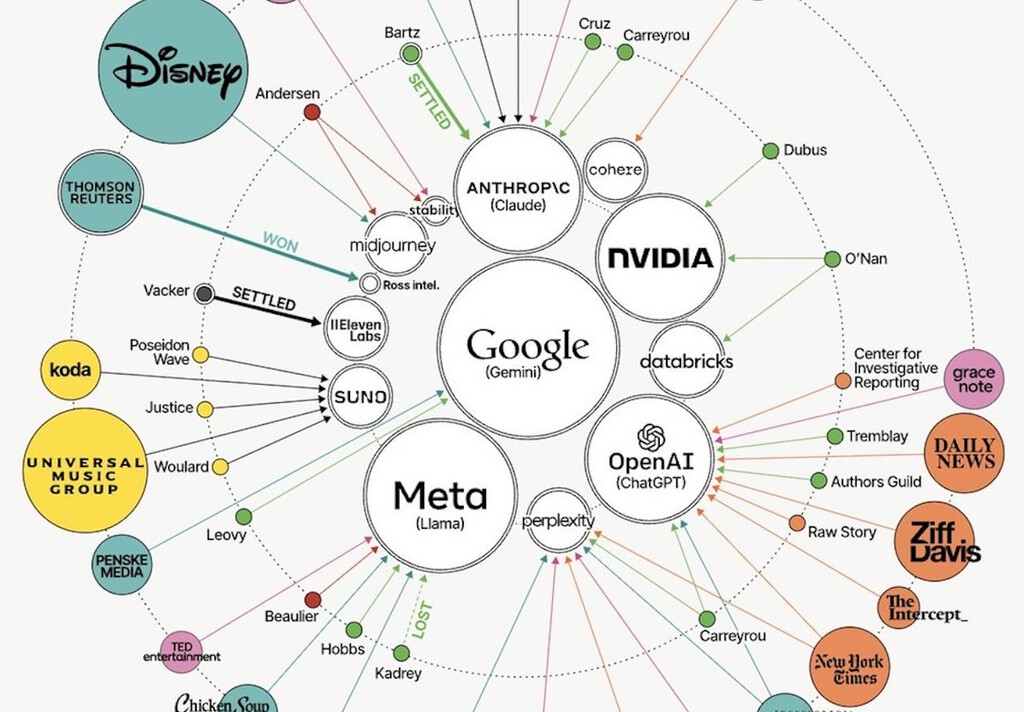
AI förberedde allt, en människa signerad Huruvida utbildning av AI-modeller med skyddat innehåll är tillåten användning eller inte är den viktigaste upphovsrättsfrågan som domstolar har ställts inför. Beroende på resultatet står företag inför en mörk framtid: att betala licenser retroaktivt, rensa databaser och naturligtvis ändra hur de samlar in sin data från och med nu. Och de har rättegångar att bära: mer än 100 aktiva klagomål i juni 2026, enligt grafen.
Det är viktigt att notera att detta diagram endast hänvisar till amerikanska domstolar. Dessutom är det en annan historia i Europa. Den gamla kontinenten har mer restriktiva regler: den kräver radering av data efter användning och tillåter kreatörer att förbehålla sig sina rättigheter.
AI-lagen kräver att man publicerar vilken data som användes i utbildningen, något som företag konsekvent har undvikit.
The work is use of David ChatGPTisEatingTheWorld.com, trådbundna rapporter och referensnyheter. Och hans arbete är lovvärt: att prata om rättstvister är inte lätt, men han har lyckats syntetisera det i en enda graf för att veta vem som stämmer vem i AI-världen. I centrum står de efterfrågade teknikföretagen och på utsidan de som efterfrågar: från skribenter till media, plattformar och artister.
Varje kategori representeras med en färg och ju större cirkel, desto större företag. Det finns också en ansvarsfriskrivning: för att grafen ska se bättre ut, när en målsägande har flera öppna stämningar, visas endast huvudsvarandens stämning. Kom igen, det är många fler än vi ser.
Vem stämmer vem. Information är vacker Kartan över konflikter På ena sidan, företagen som byggde AI-modeller, som OpenAI, Google, Meta, Anthropic, NVIDIA och Perplexity, bland andra. Till en annan, målsägande av alla slag som hävdar att deras verk använts utan tillstånd eller ersättning för att träna system som nu blivit deras konkurrens.
Summan av kardemumman är att alla stora AI-företag får förfrågningar från nästan alla kreativa kategorier. Några bra fall: Bartz v.
Anthropic. Företaget ledd av Dario Amodei gick med på att betala 1,5 miljarder dollar efter att det visades att det hade laddat ner hundratusentals böcker från inofficiella arkiv. Domstolen validerade utbildningen som tillåten användning, men inte sättet att uppnå det.
Kadrey mot mål. Mark Zuckerbergs företag vann i utbildningsdelen, men står fortfarande inför rätta för att ha distribuerat piratkopierat innehåll. New York Times vs.
OpenAI, pågår fortfarande. The Times hävdar att ChatGPT återger sina artiklar nästan ordagrant och ersätter den ursprungliga källan.Disney vs. Midjourney, fortfarande pågår: De stora underhållningsstudiorna kämpar mot bildgenereringen.
Concord, BMG och Universal vs.
Anthropic pågår fortfarande. Stora legendariska skivbolag stämmer för återgivning av skyddade texter. US Copyright Office publicerade en rapport på 108 sidor i maj 2025 som drog slutsatsen att det inte finns något universellt svar: att avgöra om användningen av verk för att träna AI är rimlig användning kräver att varje fall analyseras separat.
Och inte alla företag är likadana och inte heller alla användningsområden. Det som är tydligt är att detta system att "be om förlåtelse istället för tillåtelse" har ett pris: Anthropic har visat att det kan komma undan med att betala 1,5 miljarder dollar eftersom dess värdering är 183 miljarder dollar. Så det korta svaret är att idag har det varit värt det.
Den underliggande frågan är om det kommer att fortsätta att finnas en flod av rättsprocesser eller om det kommer att fastställas tydligare regler för användningen av data och det kommer att finnas någon med en fast hand och kunskap att tillämpa dem. I Xataka | Vem vinner egentligen AI-loppet, i en graf som sätter Google i problem I Xataka | AI kommer att generera oöverträffad rikedom. Frågan alla börjar ställa är vem som ska behålla den
Originalkälla
Publicerad av Xataka
27 june 2026, 10:00
Denna artikel har översatts automatiskt från spanska. Klicka på länken ovan för att läsa originaltexten.
Visa originaltext (spanska)
Rubrik
Quién está demandando a quién en la IA: el mapa de los 100 juicios que lo explica todo
Beskrivning
Para que ChatGPT, Gemini o Meta AI respondan bien a la ingente cantidad de preguntas que sus usuarios y usuarias le hacemos cada día, años antes las empresas que hay detrás tomaron una decisión: conseguir datos a toda costa y de donde fuera. Libros, artículos periodísticos, letras de canciones, ilustraciones, código fuente. Su premisa era clara: era mejor pedir perdón que pedir permiso. Así que hoy los juzgados están llenos de demandas, miles de millones de dólares en juego y el modelo de negocio de la IA en el banquillo. Durante años, la piratería fue cosa de particulares bajándose películas. Ahora son las mayores empresas del mundo las que han hecho algo parecido, pero a gran escala y con una tecnología que estructuralmente la vulnera. Lo que decidan los jueces marcará cómo se construye la inteligencia artificial a partir de ahora. Igual que tú te preparas mejor para un examen si además de coger el libro de clase, te vas a la biblioteca y te lees libros recomendados y amplías con otras lecturas asociadas con el tema que estés repasando, a los diferentes equipos de investigación detrás de los grandes modelos de IA se les ocurrió que con enormes datasets y de fuentes variadas el resultado era mejor. El problema es que ese tremendo volumen de datos no cae del cielo: lo cogieron de la web, de bibliotecas digitales y de repositorios LibGen o Z-Library. La defensa habitual de empresas como OpenAI es es el fair use y las excepciones de minería de texto y datos, asegurando que usan datos sin licencia de forma legítima. Así que los tribunales van caso por caso. En Xataka Un bufete de abogados IA acaba de ganar su primer juicio. La IA preparó todo, un humano firmó Si entrenar modelos de IA con contenido protegido es o no fair use es la cuestión de derechos de autor más importante a las que los tribunales se han enfrentado. En función del resultado, las empresas se enfrentan a un futuro negro: el abono de licencias de forma retroactiva, limpieza de bases de datos y por supuesto, cambiar cómo recopilan sus datos desde ya. Y tienen demandas para aburrir: más de 100 denuncias activas en junio de 2026, según el gráfico. Es importante destacar que este gráfico hace referencia únicamente a los tribunales de Estados Unidos. Además, en Europa es otro cantar. El viejo continente tiene una normativa más restrictiva: exige eliminar los datos tras usarlos y permite a los creadores reservar sus derechos. La AI Act obliga a publicar qué datos se usaron en el entrenamiento, algo que las empresas han evitado de forma sistemática. {"videoId":"x8jpy2b","autoplay":true,"title":"¿Qué hay DETRÁS de IAs como CHATGPT, DALL-E o MIDJOURNEY? | INTELIGENCIA ARTIFICIAL", "tag":"Webedia-prod", "duration":"1173"} El gráfico en cuestión es obra de David McCandless para Information is Beautiful y lo ha elaborado a partir de datos de ChatGPTisEatingTheWorld.com, reportajes de Wired y noticias de referencia. Y su trabajo es meritorio: hablar de litigios no es fácil, pero él ha conseguido sintetizarlo en un único gráfico para saber quién demanda a quién en el mundo de la IA. En el centro están las empresas tecnológicas demandadas y en el exterior, quienes demandan: desde escritores a medios pasando por plataformas y artistas. Cada categoría se representa con un color y cuanto más grande es el círculo, mayor es la empresa. Hay además un disclaimer: para que el gráfico se vea mejor, cuando un demandante tiene varias demandas abiertas, solo se muestra la del demandado principal. Vamos, que hay muchas más de las que vemos. Quién está demando a quién. Information is beautiful El mapa de los conflictosA un lado, las empresas que construyeron los modelos de IA, como OpenAI, Google, Meta, Anthropic, NVIDIA y Perplexity, entre otros. A otro, demandantes de todo tipo que alegan que sus obras fueron usadas sin permiso ni compensación para entrenar sistemas que ahora se han vuelto su competencia. El resumen es que todas las grandes de empresas de IA están recibiendo demandas de casi todas las categorías creativas. Algunos grandes casos: Bartz vs. Anthropic. La empresa liderada por Dario Amodei acordó pagar 1.500 millones de dólares tras demostrarse que había descargado cientos de miles de libros de repositorios no oficiales. El tribunal validó el entrenamiento como fair use, pero no la forma de conseguirlos.Kadrey vs. Meta. La empresa de Mark Zuckerberg ganó en la parte de entrenamiento, pero sigue en juicio por haber distribuido contenido pirata.New York Times vs. OpenAI, aún en curso. El Times alega que ChatGPT reproduce sus artículos casi literalmente, sustituyendo la fuente original.Disney vs. Midjourney, aún en curso: Los grandes estudios de entretenimiento pelean contra la generación de imágenes. Concord, BMG y Universal vs. Anthropic, aún en curso. Las grandes discográficas míticas demandan por reproducir letras protegidas.La Oficina de Derechos de Autor de EE.UU. publicó en mayo de 2025 un informe de 108 páginas concluyendo que no hay una respuesta universal: determinar si el uso de obras para entrenar IA es fair use requiere analizar cada caso por separado. Y ni todas las empresas son iguales ni todos los usos. Lo que sí que está claro es que este sistema de "pedir perdón en lugar de permiso" tiene un precio: Anthropic ha demostrado que se puede salir airosa aún pagando 1.500 millones de dólares porque su valoración es de 183.000 millones de dólares. Así que la respuesta corta es que a día de hoy, le ha merecido la pena. La cuestión de fondo es si va a seguir habiendo un aluvión de demandas o si se van a fijar normas más claras sobre el uso de datos y va a haber alguien con mano firme y conocimientos para aplicarlas. En Xataka | Quién está ganando realmente la carrera de la IA, en un gráfico que pone en aprietos a Google En Xataka | La IA va a generar una riqueza sin precedentes. La pregunta que empieza a hacerse todo el mundo es quién va a quedarse con ella (function() { window._JS_MODULES = window._JS_MODULES || {}; var headElement = document.getElementsByTagName('head')[0]; if (_JS_MODULES.instagram) { var instagramScript = document.createElement('script'); instagramScript.src = 'https://platform.instagram.com/en_US/embeds.js'; instagramScript.async = true; instagramScript.defer = true; headElement.appendChild(instagramScript); } })(); - La noticia Quién está demandando a quién en la IA: el mapa de los 100 juicios que lo explica todo fue publicada originalmente en Xataka por Eva R. de Luis .




